
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- gameplay tag
- 언리얼엔진
- Unreal Engine
- widget
- 유니티
- 언리얼 엔진
- C++
- stride
- os
- Replication
- MAC
- CTF
- ability task
- Multiplay
- rpc
- gas
- unity
- attribute
- photon fusion2
- listen server
- 보안
- Aegis
- 게임 개발
- gameplay ability system
- UI
- 게임개발
- linear regression
- local prediction
- gameplay effect
- animation
- Today
- Total
Replicated
빅데이터마이닝의 개념 본문
인공지능 > 머신러닝 > 딥러닝
인공지능
- 컴퓨터가 학습하여 스스로 판단할 수 있도록 만드는 기술
머신러닝
- 데이터를 컴퓨터에 학습시켜 그 패턴과 규칙을 컴퓨터가 스스로 학습하도록 만드는 기술
딥러닝
- 머신러닝 기법 중 신경망을 기반으로 사물으로 데이터를 군집화하거나 분류하는데 사용하는 기술
머신러닝의 기본 모형
ŷ = f(x)
독립변수 x, 예측값 ŷ
머신러닝을 통해 f를 찾음
전통적인 프로그래밍 접근
(규칙 + 데이터) -> 기계 -> 결과
(결과 + 데이터) -> 기계 -> 규칙
피쳐(Feature)?
- 특성이나 특징
y = ax + b
여기서 피쳐는 x
알고리즘을 통해 a와 b의 최적값을 찾음
피쳐의 표기법
- 데이터 테이블(data table) : 데이터를 테이블로 표현한 것
- 데이터 인스턴스 : 하나의 데이터 == 튜플 == 엑셀의 한 행
- 튜플의 값은 열 벡터로 표현하고 가중치도 열벡터로 표현
- 수식을 선형 대수 표기법으로 표현 : W^TX
- 벡터의 내적. 열 벡터끼리 같은 위치에 있는 값들을 곱해서 최종적으로 모두 더하기
차원의 저주
- 실제 머신 러닝에서는 피쳐의 개수가 크게 증가
- 필요에 따라 차원 축소, 차원 제거 등 사용
데이터 분류
- 연속형 데이터 : 값이 끊어지지 않고 이어짐
- 이산형 데이터 : 연속적 값이 아니라 분리해서 표현하는 데이터로 일종의 라벨
- 차이는 숫자의 의미가 스케일이 있는가 없는다
* 서수형 타입 : 범주형 데이터의 일종이나, 데이터 간 순서가 존재(ex. 대/중/소)
import pandas as pd # (1) pandas 모듈 호출
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
# (2) 데이터 URL을 변수 data_url에 넣기
df_data = pd.read_csv(data_url, sep='\s+', header = None) # (3) csv 데이터 로드
df_data.columns = ['CRIM','ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO' ,'B', 'LSTAT', 'MEDV'] # (4) 데이터의 열 이름 지정
df_data.head() # (5) 데이터 출력
url 받고 read_csv(경로, 구분자, 헤더)
구분자 '\s+' : 공백(스페이스, 탭) 한 개 이상을 구분자로 쓴다는 뜻
header None : 첫번째 행을 열 이름으로 쓰지 않는다
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
# (2) 데이터 URL을 변수 data_url에 넣기
df_data = pd.read_csv(data_url, sep='\s+', header = None) # (3) csv 데이터 로드
df_data.columns = ['CRIM','ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE',
'DIS', 'RAD', 'TAX', 'PTRATIO' ,'B', 'LSTAT', 'MEDV'] # (4) 데이터의 열 이름 지정
df_data.head() # (5) 데이터 출력
import numpy as np # (1) numpy 모듈 호출
df_data['weight_0'] = 1 # (2) weight 0 값 추가
df_data = df_data.drop("MEDV", axis=1) # (3) Y 값 제거
df_matrix = df_data.values # (4) 행렬(Matrix) 데이터로 변환하기
weight_vector = np.random.random_sample((14, 1)) # (5) 가중치 w 생성
df_matrix.dot(weight_vector) # (6) 내적 연산 실행 결과 출력
랜덤한 14 길이 가중치 벡터 생성 후 내적한 결과
* gpt가 알려주는 내적


이런식으로 계산됨
판다스
- 파이썬 데이터 분석 라이브러리, 데이터 테이블을 다루는 도구
- 넘파이 사용
데이터프레임
- 데이터 테이블 전체 객체
- 시리즈 : 각 열 데이터를 다루는 객체
시리즈 객체 == 피쳐 벡터
import pandas as pd # pandas 모듈 호출
import numpy as np # numpy 모듈 호출
from pandas import Series, DataFrame
list_data = [1,2,3,4,5, 6]
list_name = ["a","b","c","d","e", "a"]
example_obj = Series(data = list_data, index=list_name)
example_obj

리스트로 시리즈 만들기
Series()로 리스트 데이터와 인덱스 만들기 가능
dict_data = {"a":1, "b":2, "c":3, "d":4, "e":5}
example_obj = Series(dict_data, dtype=np.float32,
name="example_data")
example_obj
딕셔너리로 시리즈 만들기
dict_data_1 = {"a":1, "b":2, "c":3, "d":4, "e":5}
indexes = ["a","b","c","d","e","f","g","h"]
series_obj_1 = Series(dict_data_1, index=indexes)
series_obj_1
없는 인덱스 추가하면 NaN
import pandas as pd # (1) pandas 모듈 호출
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
df_data = pd.read_csv(data_url, sep='\s+', header = None) # (3) csv 데이터 로드
df = pd.DataFrame(df_data)
df
데이터 프레임 만들기
from pandas import Series, DataFrame
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas',
'Boston']}
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city'])
df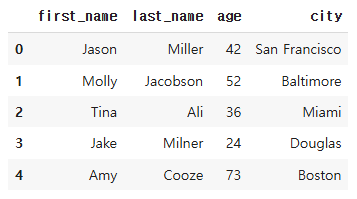
컬럼 뭐 쓸지도 설정 가능
DataFrame(raw_data, columns = ["age", "city"])
컬럼 일부만도 가능
import pandas as pd # pandas 모듈 호출
import numpy as np # numpy 모듈 호출
!wget https: 파일 어딘가..
file_path = '/content/excel-comp-data.xlsx'
df = pd.read_excel(file_path)
df.head(5)
파일
df[["account", "street", "state"]].head(3)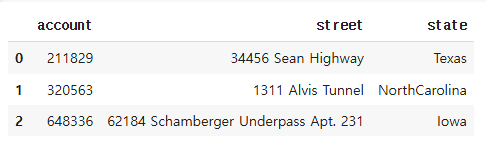
컬럼으로 빼오기
df[:3]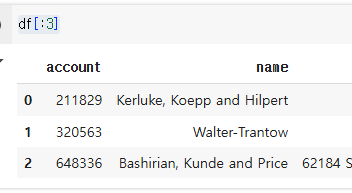
3행 전까지 출력
df[["name","street"]][:2]
# 트레이닝 데이터랑 테스트 데이터 분리하는 방식
열과 행으로 빼오기
df.index = df["account"]
del df["account"]
df.head()
인덱스 설정
df.loc[[211829,320563],["name","street"]]
loc는 행, 열 순서
df.loc[205217:,["name","street"]]
인덱싱 시 이상값을 정렬 안된 채로 줌
df.iloc[:10, :3]
iloc는 행 번호, 열 번호로 지정
써놓은 거 이전까지 보여줌
df_new = df.reset_index()
df_new
reset_index 시 인덱스는 열로 부활
df_new.drop(1).head()1번 행 삭제
열 삭제시 axis=1 지정 필요
병합
- 두 개의 데이터를 특정 기준을 가지고 하나로 통합하는 작업
import pandas as pd # pandas 모듈 호출
raw_data = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_score': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
df_left = pd.DataFrame(raw_data, columns = ['subject_id', 'test_score'])
df_left왼쪽 집합
raw_data = {
'subject_id': ['4', '5', '6', '7', '8' ],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
df_right = pd.DataFrame(raw_data, columns = ['subject_id', 'first_name', 'last_name'])
df_right오른쪽 집합
내부조인 (교집합)
- 키 값을 기준으로 두 테이블에 모두 존재하는 키 값의 행끼리 병합
pd.merge(left=df_left, right=df_right, how="inner", on='subject_id')
완전 조인 (합집합)
- 두 개의 테이블에서 각각의 행을 병합. 두 테이블에서 동일한 키 값을 가진 행은 통합, 두 테이블 중 하나라도 키 값이 존재하지 않는다면 존재하는 쪽의 데이터만 남겨줌 (없으면 NaN)
pd.merge( df_left, df_right, on='subject_id', how='outer')
왼쪽 조인 (왼쪽만 남기기)
- 왼쪽 테이블의 값을 기준으로 같은 키 값을 소유하고 있는 행을 병합, 오른쪽 테이블에 해당 키 값이 없으면 해당 행은 삭제
pd.merge( df_left, df_right, on='subject_id', how='left')
오른쪽 조인 (오른쪽만 남기기)
- 오른쪽 테이블의 값을 기준으로 같은 키 값을 소유하고 있는 행을 병합, 왼쪽 테이블에 해당 키 값이 없으면 해당 행은 삭제
pd.merge( df_left, df_right, on='subject_id', how='right')
연결 - 두 테이블 그대로 붙임
pd.concat([df_left, df_right], axis=0)

세로로 연결됨
'학부 > 빅데이터마이닝' 카테고리의 다른 글
| 경사하강법 실습 (0) | 2025.04.08 |
|---|---|
| 경사하강법의 종류 (0) | 2025.04.07 |
| 경사하강법 선형회귀 (0) | 2025.04.07 |
| 최소자승법 선형회귀 - 수식 유도, 장단점 (0) | 2025.04.07 |
| 선형 회귀, MSE (0) | 2025.04.07 |


