
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Aegis
- gameplay tag
- gas
- 유니티
- unity
- animation
- Unreal Engine
- Multiplay
- Replication
- local prediction
- 게임개발
- C++
- listen server
- 언리얼 엔진
- gameplay effect
- widget
- linear regression
- MAC
- 보안
- stride
- gameplay ability system
- 언리얼엔진
- os
- ability task
- 게임 개발
- CTF
- photon fusion2
- attribute
- rpc
- UI
- Today
- Total
Replicated
어휘 분석 본문
어휘 분석(lexical analysis)
- 소스 프로그램을 읽어 토큰(token)이라는 문법적으로 의미있는 최소의 단위로 분리하는 것으로 토큰 스트림(stream)을 출력
- 어휘 분석 도구를 어휘 분석기(lexical analyzer) 또는 스캐너(scanner)라 함
어휘 분석기 기능
- 토큰을 인식
- 전처리 과정(preprocessing): 코멘트, 화이트 스페이스, 탭, 뉴 라인, 매크로 등을 처리
- 기호표 (symbol table) 구성
- 에러 처리에 대한 진단
용어
- 토큰(Token) : 문법에 있는 터미널 기호들로 구성된 문법적으로 의미있는 최소 단위
- 패턴(Pattern) : 토큰을 서술하는 규칙들
- 렉심(Lexeme) : 패턴에 의해 매칭된 문자열
일반적인 프로그래밍 언어에서 사용하는 토큰들
Special form - language designer
1. 지정어(keyword) : for, if, int 등의 언어에 이미 정의된 단어
2. 연산자 기호(operator symbol) : +, -, *, /, <, =, ++ 등의 연산 기호
3. 구분자(delimiter) : ;, (, ), [, ] 등 단어와 단어를 구분하거나 문장과 문장을 구분하는 기호
General form - programmer
4. 식별자(identifer) : abc, b12, sum 등 프로그래머가 정의하는 변수
5. 상수(constant) : 526, 3.0, 0.1234e-10, 'str' 등 실수형, 정수형, 문자형 상수
패턴
패턴들은 정규 문법에 의해 서술
- C 언어의 식별자: 첫번째 기호가 영문자 소문자나 대문자 혹은 언더바(_)로 시작하고 두번째 기호부터는 영문자 소문자나 대문자, 숫자, 언더바가 오는 것
- <ident> ::= ( <letter> | _ ){ <letter> | <digit> | _ }
- <letter> ::= a | b | c| ... | z | A | B | ... | Z
- <digit> ::= 0 | 1 | ... | 9
- 괄호는 이 중 하나를 선택해라, 중괄호는 0번 이상 반복
토큰 스트림 구하기
ni = ba * po - 60 + ni / (abc + 50);
ni, =, ba, *,
po, -, 60, +,
ni, /, (, abc,
+, 50, ), ;
토큰 스트림은 위와 같이 16개, 순서대로 분리
토큰, 렉심, 패턴 구하기
| 토큰 | 렉심 | 패턴 |
| 식별자 | ni, ba, po, abc | 첫 자가 영문자나 언더바이고 둘 째 자부터는 영문자나 숫자, 언더바 |
| 연산자 | 치환 연산자(=), 더하기 연산자(+), 빼기 연산자(-), 곱하기 연산자(*), 나누기 연산자(/) |
치환 연산자(=), 산술 연산자(+, -, *, /) |
| 상수 | 60, 50 | 어떤 정수형 숫자 상수 |
| 구분자 | (, ), ; | 문장 사이를 구분해 주는 구분자 |
토큰의 표현
- 효율적인 구문 분석을 위해 토큰을 토큰 번호(token number)와 토큰 값(token value)의 순서쌍으로 표현
- 토큰 번호: 각각의 토큰들을 구분하기 위해 각각의 토큰들에게 고유의 내부 번호를 부여한 정수 코드
- 토큰 값: 토큰들 중에 식별자나 상수는 하나의 이름으로 여러번 사용될 수 있으므로 여러 번 사용될 때마다 다르게 표현하는 것이 아니라 프로그래머가 사용한 값으로 구별하기 위한 값
- 식별자나 상수의 토큰 값은 기호표의 식별자나 상수가 위치하는 포인터값
* (10, -) => 이런 식으로 표현되면 토큰 값이 없음.. 식별자로 기호표에 저장된 위치의 값이 토큰 값
* 상수는 토큰 값이 상수 값일 수도 있고, 포인터 따라가야 할 수도 있고
토큰의 인식
- 토큰의 구조 : 정규 표현을 사용해서 표현
- 인식기는 정규 표현을 받아들이는 유한 오토마타를 구성
*밑부터 편의 상 letter는 l로, digit는 d로 표현
Identifier(식별자) 인식
- C언어 용 상태 전이도

정규 문법
S -> lA | _A
A -> lA | dA | _A | ε
정규 표현 변환
S = lA + _A = (l + _)A
A = lA + dA + _A + ε = (l + d + _)A + ε = (l + d + _)*
S = (l + _)(l + d + _)*
예약어 인식
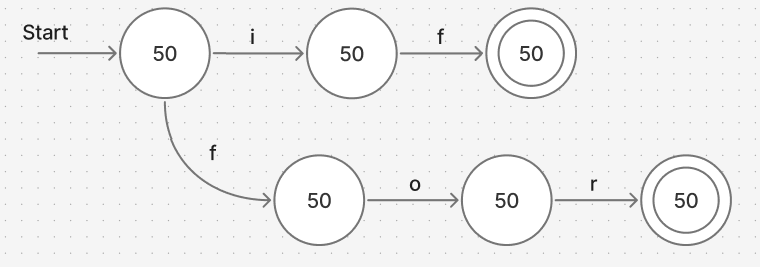
if, for 읽기
정수의 인식

10진법 양의 정수에 대한 상태 전이도
정규 문법을 거쳐 정규 표현으로 변환하면?
S->dC
C->dC | ε
S = dC
C = dC + ε = d*
S = dd* = d*
실수 상수의 인식
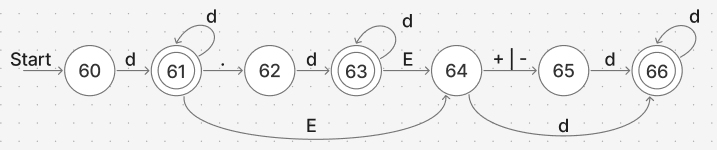
ex. 12.56, 10E+2, 123.25E-10
정규 문법
S->dA
A->dA | .B | eD | ε
B->dC
C->dC | eD | ε
D->+E | -E | dF
E->dF
F->dF | ε
F = d*
E = dd* = d+
D = ( '+' + - )d+ + d* = ( ε + '+' + - )d+
C = dC + e( ε + '+' + - )d+ + ε = d*( e( ε + '+' + - )d+ + ε )
B = dd*( e( ε + '+' + - )d+ + ε ) = d+( e( ε + '+' + - )d+ + ε )
A = dA + .B = d*.d+( e( ε + '+' + - )d+ + ε )
S = dA (뒷부분 너무 길어 그냥 이렇게 계산한다 정도로 생략)
= d+.d+( e( ε + '+' + - )d+ + ε )
= d+.d+ + d+.d+e( ε + '+' + - )d+
주석의 처리
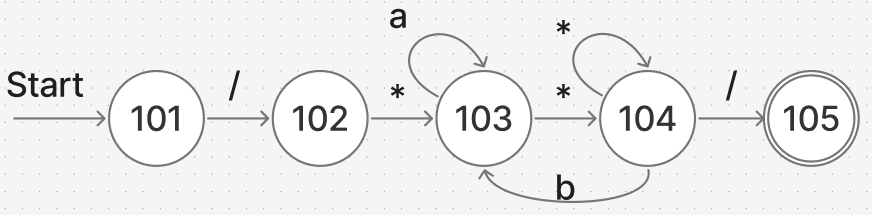
단, a는 * 이외의 모든 문자, b는 *와 /을 제외한 모든 문자
S->/A
A->*B
B->aB | *C
C->*C | /D | bB
D->ε
C = *C + /D + bB
= *C + / + bB = **(bB + /)
B = aB + *C
= aB + ***(bB + /) = aB + *+bB + *+/ // *** 이게 엄청 헷갈리게 생겼는데, '*' 뒤에 '*'* 이 붙은 거라 *+가 됨
= (a + *+b)B + *+/
= (a + *+b)*(*+/)
A = *(a + *+b)*(*+/)
S = /*(a + *+b)*(*+/)
어휘분석기의 설계 및 구현
1. 이론적인 방법들을 프로그래밍을 통하여 구현
2. 렉스(플렉스)를 통해서 구문 분석기를 생성
프로그래밍 기법
- 문법이 있어야 하고, 문법에서 사용하는 토큰과 토큰에 대한 패턴을 찾아야 함
- 토큰과 패턴을 찾아 토큰표를 만들고 그것을 정규 문법으로 표현한 다음, 다시 정규 표현으로 나타냄
- 그리고 다시 정규 표현을 받아들이는 NFA를 구현하고 DFA로 변환한 뒤, 상태수를 최소화시키면 어휘분석기임
'학부 > 오토마타와 컴파일러' 카테고리의 다른 글
| 모호한 문법 (0) | 2025.11.24 |
|---|---|
| 문맥 자유 문법과 파스 트리 (0) | 2025.11.23 |
| 정규 언어, 정규 문법, 유한 오토마타의 동치 관계 (0) | 2025.10.12 |
| DFA의 상태수 최소화 (0) | 2025.10.12 |
| NFA의 DFA 변환 및 ε-전이 (0) | 2025.10.11 |