
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 유니티
- UI
- stride
- attribute
- MAC
- unity
- network object pooling
- CTF
- local prediction
- 보안
- gas
- Aegis
- gameplay tag
- nanite
- 언리얼엔진
- animation
- photon fusion2
- os
- Unreal Engine
- listen server
- 게임 개발
- gameplay effect
- 게임개발
- map design
- 언리얼 엔진
- Replication
- ability task
- gameplay ability system
- rpc
- Multiplay
- Today
- Total
Replicated
Lab #2 : Concurrent Binary Search Tree 본문
https://github.com/Lagooneng/ConcurrentBST
GitHub - Lagooneng/ConcurrentBST: Concurrent Binary Search Tree
Concurrent Binary Search Tree. Contribute to Lagooneng/ConcurrentBST development by creating an account on GitHub.
github.com
싱글 스레드,
Coarse-grained lock, Fine-grained lock (1, 2, 4, 8 스레드)에서 성능 분석
* 삽입, 삽입-탐색, 삽입-탐색-삭제 세 가지 상황 존재
1. Lock Type(Non, Coarse, Fine)과 Thread 수에 따른 실행시간 비교 분석

* 자세한 분석을 위해 할당하는 코어를 다르게 하였다
데이터(버츄얼 박스 4코어 / 1코어 할당 테스트)이다. 비교를 위해 각 INSERT_ONLY, INSERT_LOOKUP, INSERT_LOOKUP_DELETE 수행 시간의 평균을 기반으로 그래프를 만들어 비교한다.
a. Single Thread에서 최악의 실행 시간을 가지는 것은 무엇인가

위 그래프는 4코어 환경에서 싱글스레드로 기본 BST, CoarseBST, FineBST를 실행시킨 시간을 나타낸 것이다. 기본 BST와 CoarseBST는 시간이 크게 차이가 나지 않지만, FineBST가 2~3배 가량 실행 시간에 차이가 걸리는 것을 확인할 수 있다. 기본적으로 싱글 스레드로 실행되기 때문에, 병렬성을 위해 추가된 복잡한 락 구조가 오히려 실행에 부정적인 영향을 끼쳤다고 알 수 있다. CaorseBST의 경우 일단 락, 언락을 하는 코드가 있어 기본 BST보다 느리지만 구조가 복잡하지 않아 시간에 큰 차이가 나지 않는 것을 알 수 있다.
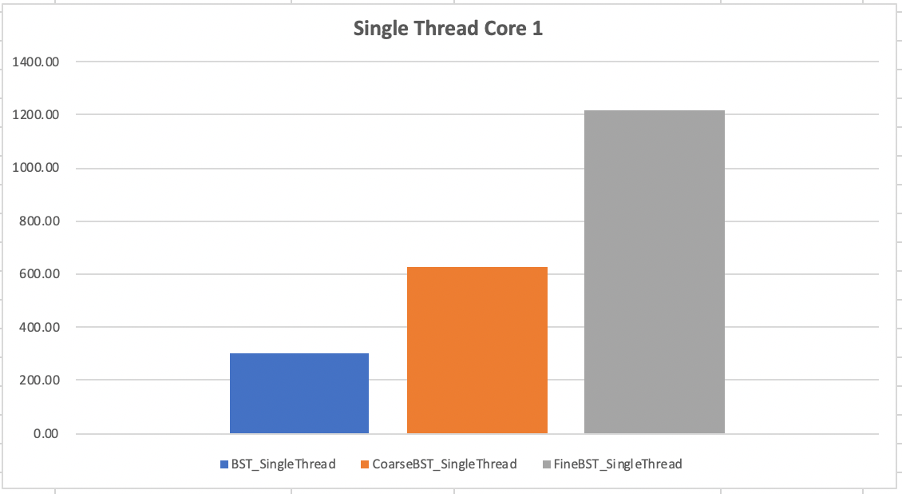
버츄얼 박스의 설정에서 코어를 1개로 바꾸고 테스트한 결과이다. 싱글 스레드에서 가장 실행 시간이 좋지 못한 것은 FineBST였다. 이를 통해 알 수 있는 것은, 락을 사용할 필요가 없는 경우엔 사용하지 않는게 성능에 가장 좋다는 것이다. 굳이 싱글 스레드에 한정하지 않더라도, 공유 자원을 사용하지 않는다면 멀티 스레드 환경에서도 락을 사용할 필요가 없을 것이다.
b. Multi Thread에서 Coarse BST와 Fine BST에서 더 좋은 실행 시간을 가지는 것은 무엇인가
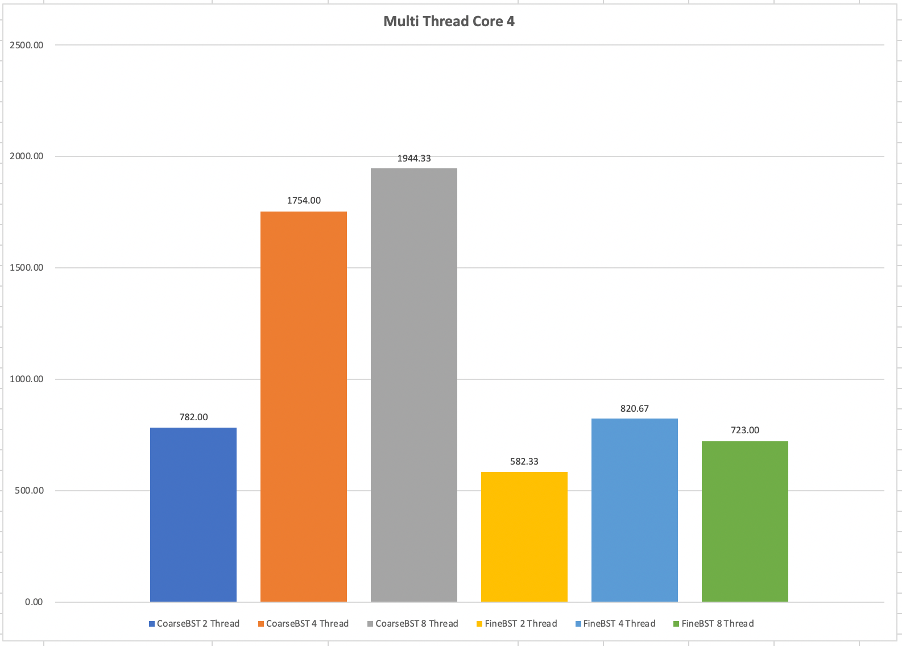
4코어 환경에서 각 스레드 개수 별 CoarseBST와 FineBST의 성능을 비교한 그래프이다. 가장 좋은 성능을 보이는 것은 2 스레드에서의 FineBST였다. 2스레드 CaorseBST의 경우 4스레드 FineBST보다 미묘하게 좋기는 하지만, 이 정도 차이는 실행 시마다 달라진다. , 8스레드의 경우 CoarseBST가 2배 이상 느린 모습을 보여준다. 확실히 트리 전체에 락을 하는 것보단, 개별 노드마다 락을 하는 것이 멀티 스레드 환경에선 좋은 것으로 나타난다.
2스레드일 때 CoarseBST의 경우 그나마 좋은 실행 시간을 보여주는데 스레드가 2개라 충돌이 4스레드, 8스레드보다 비교적 적게 발생하여 실행 시간이 그나마 좋다고 분석할 수 있다.
이를 통해 알 수 있는 것은, 구조 자체는 복잡해도 멀티 스레드 환경에서는 Fine-grained Lock이 확실히 좋은 성능을 보여준다는 것이다. 또한, 무조건 스레드를 많이 만드는게 성능에 좋은 영향을 주는 것이 아니라는 것을 알 수 있다. 락을 어떻게 사용하느냐에 따라 싱글 스레드가 차라리 더 실행 시간이 좋을 수도 있고, 스레드를 늘렸더니 오히려 수행 시간이 길어질 수도 있다.
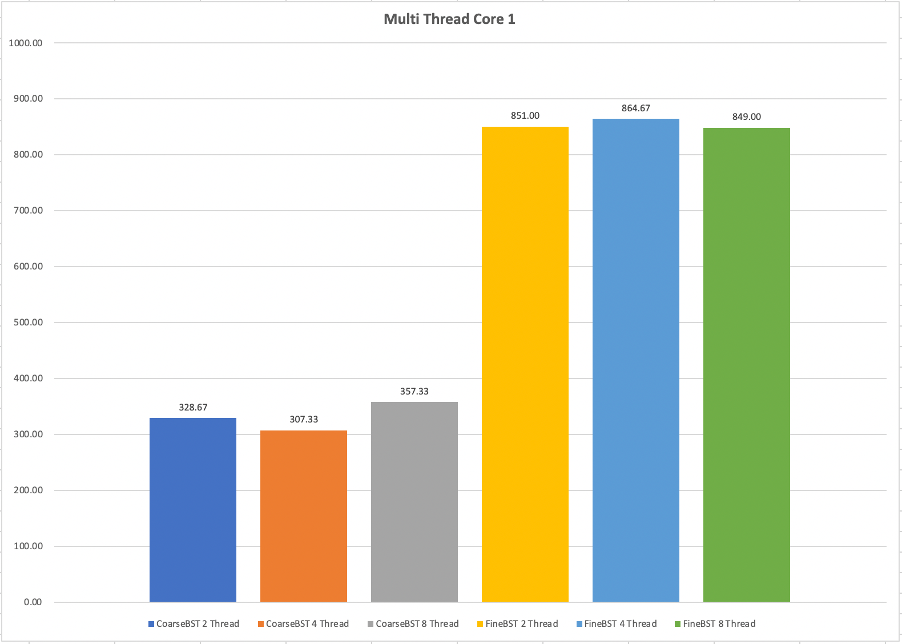
위 그래프는 버츄얼 박스에서 코어를 1개 할당했을 때, 멀티 스레드 환경에서 CoarseBST와 FineBST를 비교한 것이다. 코어가 4개일 때랑 비교하면, 반대의 결과이다. 스레드를 아무리 늘려도 실행되는 코어는 1개이기에 충돌이 발생하는 일이 코어가 4개일 때보다 현저히 적어진다. 이렇게 되면, 오히려 구조가 복잡한 FnieBST가 더 성능이 안좋아진다. 반면 CoarseBST는 코어가 4개일 때보다 훨씬 좋은 성능을 보여준다.
처음에 CoarseBST에서 8스레드인 경우엔 그래도 충돌이 많이 발생하여 속도가 느리지 않을까 생각하였으나, 굉장히 큰 차이로 FineBST가 느렸다. 스레드의 개수도 중요하지만, 어떤 환경에서 실행되느냐가 매우 중요한 조건임을 알 수 있었다. 여러 번의 수행에서 어느정도 CoarseBST가 FineBST에 근접하게 느린 경우도 있었지만, 거의 대부분의 경우 CoarseBST와 FineBST 간 수행 시간은 분명한 차이를 보였다.
** Lab3는 파일 시스템 포렌식인데, 개인 정보가 너무 많이 나와서 스킵합니다.
'운영체제' 카테고리의 다른 글
| Lab #1 : Process Scheduler Simulating (0) | 2024.12.29 |
|---|---|
| Swap / Replacement Policies / Thrashing (0) | 2024.06.17 |
| Paging (페이징)과 TLB (0) | 2024.06.16 |
| Segmentation (세그멘테이션) (0) | 2024.06.15 |
| 메모리 가상화 - introduction (0) | 2024.06.15 |
